
在 Day 20 我們介紹了 KEDA,談到如何根據事件驅動自動調整 Pod 的數量,進一步提升叢集的資源彈性。這其實是一個里程碑:代表我們已經把基礎設施的骨架搭建完畢,從基礎資源(Karpenter)、流量入口(Ingress NGINX、Load Balancer Controller)、DNS(ExternalDNS)、到監控告警(Prometheus + Grafana + Alertmanager)都準備就緒。
因此今天我們會回到另一個環節:Code Delivery,畢竟再完美的基礎設施,如果應用程式不能快速、安全、持續地交付,也只是個空架子。Day 21 的主題就是把我們的 CI/CD pipeline 講清楚,看看如何讓程式碼從 Git commit 開始,一路走到映像檔建置,再交給 ArgoCD 進行部署,形成完整的 GitOps 閉環。
我們的 pipeline 採用 GitLab CI,分成兩個主要的 stage:test 和 build。這樣設計的原因是希望在流程的早期就盡快攔截錯誤,而不是到最後推送映像檔的時候才發現。
在 test 階段,我們做三件事:
terraform fmt 和 tflint。這樣的好處是,如果一個 MR 改壞了 Dockerfile、Terraform、或引入了敏感字串,問題能在 merge 之前就被阻止,避免浪費後續的 runner 資源。
到了 build 階段,我們才真正生成並推送映像檔。這裡我們嚴格依賴 tag 規則 來決定要建置哪個服務、哪個版本。例如:
dev/frontend/1.2.3
staging/backend/2.0.0
透過這種設計,開發者不需要修改 YAML,也不需要自己手動標記映像檔,只要打對 tag,Pipeline 就會自動把結果推送到正確的 ECR repo。這樣的規則化,讓 CI/CD 不會隨人員習慣而變動,降低了錯誤風險,也更符合 GitOps「宣告式」的精神。
在早期,我們的 pipeline 使用的是 Docker buildx。那個流程看起來大致是這樣:
before_script:
- # 安裝 Docker 和 buildx plugin
- curl -fsSLO https://download.docker.com/linux/static/stable/x86_64/docker-${DOCKER_VERSION}.tgz
- # ... (省略詳細步驟)
script:
- app=$(echo "$CI_COMMIT_TAG" | awk -F_ '{print $1}')
- tag=$(echo "$CI_COMMIT_TAG" | awk -F_ '{print $2}')
- docker buildx build --load --build-arg APP=$app \
-t $ECR/example-project/$app:$tag \
--cache-to type=registry,ref="$CI_REGISTRY_IMAGE:$app-cache",mode=max \
--cache-from type=registry,ref="$CI_REGISTRY_IMAGE:$app-cache" .
- docker push $ECR/example-project/$app:$tag
但這種方式每次建置都要花 5~10 分鐘,太耗時了。後來我們換成 Kaniko,時間直接降到 2 分鐘左右。這差異來自於:
不過在我寫這篇筆記的現在,Kaniko 已經進入 Archive 階段,因此我們預計在未來會改採用 buildkit 來作為我們 CI script 中建立 image 的工具。
我們的映像檔會推送到 AWS ECR,命名規則是:
example-project/<service>/<environment>:<tag>
例如:
example-project/backend/dev:1.2.3
example-project/frontend/staging:2.0.0
這樣的策略不只清楚,也和我們的 GitOps 流程緊密相連。因為版本號完全來自 Git tag,所以不用擔心手動標記導致版本漂移,保證了 CI → Registry → CD 的一致性。
為了要更方便的 pull ECR 上最新的、指定的 image,我們一樣採用 Helm Manager 的架構來部署 ArgoCD Image Updater 這張 Helm chart。在 Day 13 的 App-of-Apps 架構裡,我們每個 Application 都能加上 Image Updater 的 annotation。例如:
metadata:
name: testing-worker
namespace: {{ .Values.project }}
annotations:
argocd-image-updater.argoproj.io/image-list: worker=123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/example-project/worker/testing
argocd-image-updater.argoproj.io/worker.update-strategy: semver:~1.2
argocd-image-updater.argoproj.io/worker.helm.image-name: deploy.image.name
argocd-image-updater.argoproj.io/worker.helm.image-tag: deploy.image.tag
argocd-image-updater.argoproj.io/write-back-method: argocd
這些 annotation 定義了:
image.name 與 image.tag)我們實際採用的策略是:
latest,方便快速測試。semver,例如 semver:~1.2,代表只接受 1.2.x 的更新,不會自動升到 1.3。這樣能兼顧自動化與穩定性。它不會打 commit 回 Git repo,因為對我們來說追蹤 image tag 是 image updater 的工作,我們沒有必要再在 GitLab 維護一份 image tag 的資訊。Git repo 保存 chart 與 values 的框架,而具體的映像檔版本由 pipeline 與 Image Updater 推進即可。
這裡有一個很重要的觀念:CI 負責產生映像檔,CD 負責消化映像檔。CI 的責任結束於「推到 ECR」,而 CD 的責任開始於「把最新的 image 套到 cluster」。這中間靠的就是 Image Updater,真正把 CI 與 CD 黏在一起。
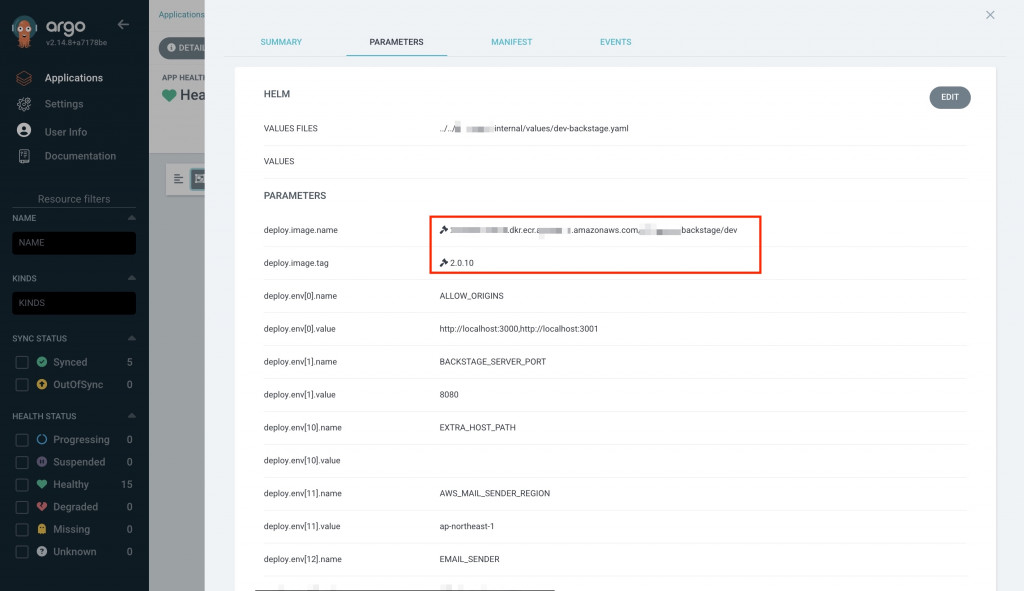
在我們有正確設定 Image Updater 的情況下,我們就能看到 Application 的 image name 會被 Image Updater 改成我們在 Application 上所指定的值,以及 image tag 則會被 Image Updater 根據 annotation 選最新的 semver。
如果把整個流程攤開來,可以用文字畫出這樣一個閉環:
[Developer Commit & Tag]
↓
[GitLab CI Pipeline]
↓
[Kaniko Build Image]
↓
[Push to ECR Registry]
↓
[ArgoCD Image Updater 偵測新版本]
↓
[ArgoCD 套用到 Cluster]
↓
[Application Running]
↺
(下一次 Commit 再啟動新一輪)
這就是我們的 GitOps 閉環:
今天我們走完了 CI/CD 的另一半:
至此,我們已經不只是建好 infra,而是真正讓程式碼能夠「流動」起來。從 commit 到 deployment,全部自動化,這才是 GitOps 的精髓。
到這邊為止,我們已經算是完成了最基本可交付的 Kubernetes 叢集架構。從 Day 1 到 Day 21 介紹的內容都是我在作為 SRE 所學到的基本知識。至於從明天開始,我們會進一步討論架構上更進階,或者 Kubernetes 在網路底層的運作有關的介紹與研究。最後幾天我們一起加油吧 🪴
